Apache Kafka
Apache Kafka is a distributed streaming platform.
Why use Apache Kafka?
Its abstraction is a queue and it features
- a distributed pub-sub messaging system that resolves N^2 relationships to N. Publishers and subscribers can operate at their own rates.
- super fast with zero-copy technology
- support fault-tolerant data persistence
It can be applied to
- logging by topics
- messaging system
- geo-replication
- stream processing
Why is Kafka so fast?
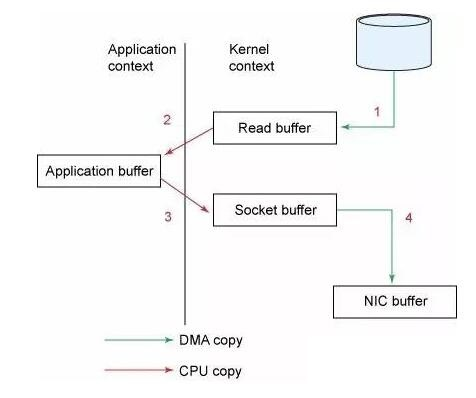
Kafka is using zero copy in which that CPU does not perform the task of copying data from one memory area to another.
Without zero copy:
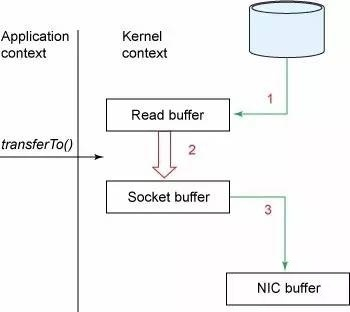
With zero copy:
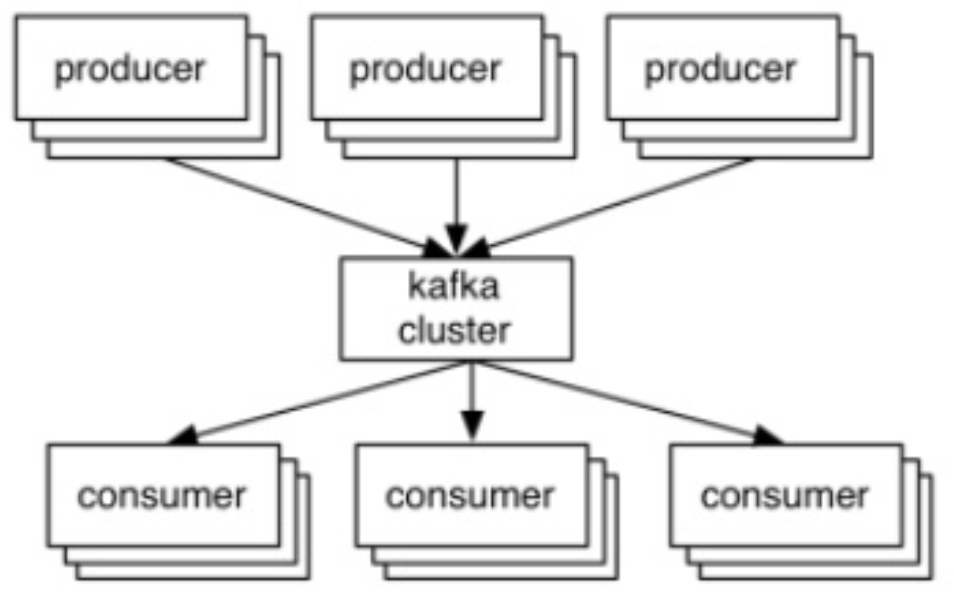
Architecture
Looking from outside, producers write to brokers, and consumers read from brokers.
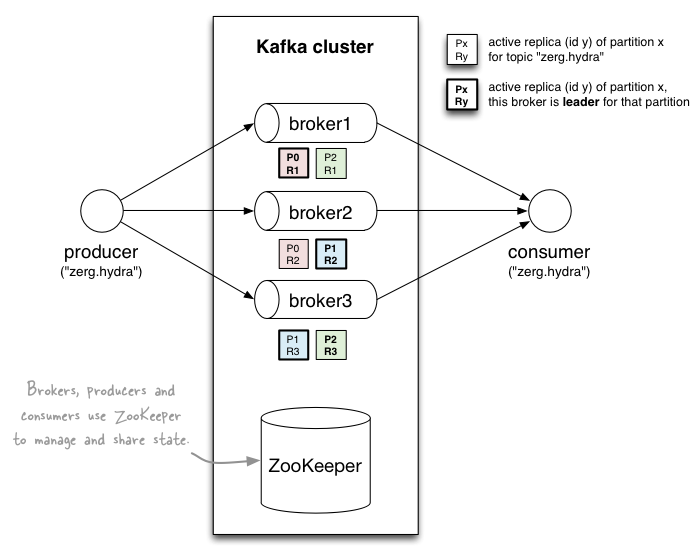
Data is stored in topics and split into partitions which are replicated.
- Producer publishes messages to a specific topic.
- Write to in-memory buffer first and flush to disk.
- append-only sequence write for fast write.
- Available to read after write to disks.
- Consumer pulls messages from a specific topic.
- use an “offset pointer” (offset as seqId) to track/control its only read progress.
- A topic consists of partitions, load balance, partition (= ordered + immutable seq of msg that is continually appended to)
- Partitions determine max consumer (group) parallelism. One consumer can read from only one partition at the same time.
How to serialize data? Avro
What is its network protocol? TCP
What is a partition’s storage layout? O(1) disk read
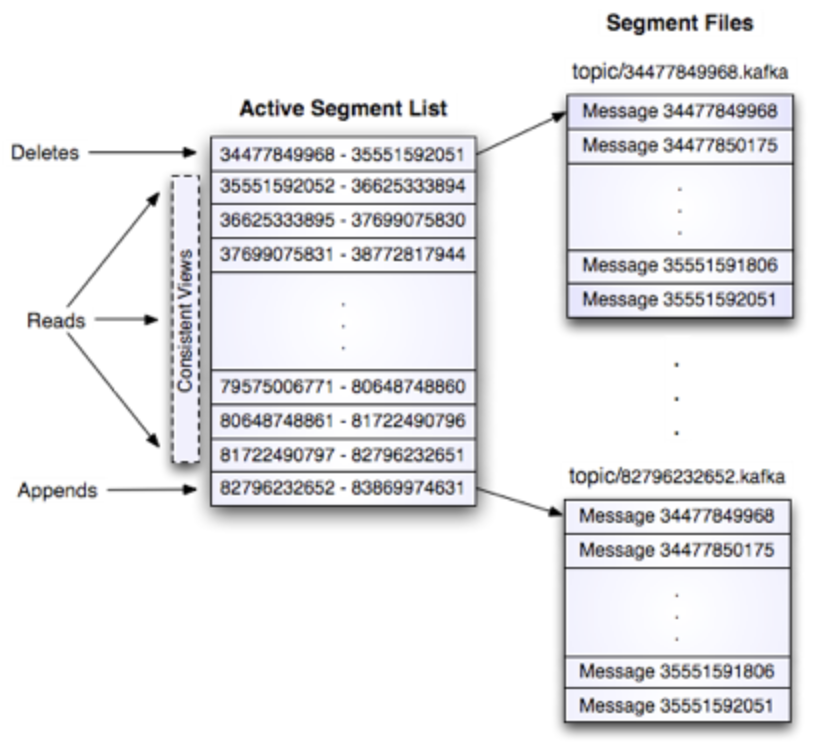
How to tolerate fault?
In-sync replica (ISR) protocol. It tolerates (numReplicas - 1) dead brokers. Every partition has one leader and one or more followers.
Total Replicas = ISRs + out-of-sync replicas
- ISR is the set of replicas that are alive and have fully caught up with the leader (note that the leader is always in ISR).
- When a new message is published, the leader waits until it reaches all replicas in the ISR before committing the message.
- If a follower replica fails, it will be dropped out of the ISR and the leader then continues to commit new messages with fewer replicas in the ISR. Notice that now, the system is running in an under replicated mode. If a leader fails, an ISR is picked to be a new leader.
- Out-of-sync replica keeps pulling message from the leader. Once catches up with the leader, it will be added back to the ISR.
Is Kafka an AP or CP system in CAP theorem?
Jun Rao says it is CA, because “Our goal was to support replication in a Kafka cluster within a single datacenter, where network partitioning is rare, so our design focuses on maintaining highly available and strongly consistent replicas.”
However, it actually depends on the configuration.
Out of the box with default config (min.insync.replicas=1, default.replication.factor=1) you are getting AP system (at-most-once).
If you want to achieve CP, you may set min.insync.replicas=2 and topic replication factor of 3 - then producing a message with acks=all will guarantee CP setup (at-least-once), but (as expected) will block in cases when not enough replicas (<2) are available for particular topic/partition pair.


Comments
Post a Comment